
本章要先浏览一下内核发出的启动信息,然后再逐个讲解一些有意思的点。
2.1 启动过程
图2-1显示了基于x86计算机Linux系统的启动顺序。第一步是BIOS从启动设备中导入主引导记录(MBR),接下来MBR中的代码查看分区表并从 活动分区读取GRUB、LILO或SYSLINUX等引导装入程序,之后引导装入程序会加载压缩后的内核映像并将控制权传递给它。内核取得控制权后,会将 自身解压缩并投入运转。
基于x86的处理器有两种操作模式:实模式和保护模式。在实模式下,用户仅可以使用1 MB内存,并且没有任何保护。保护模式要复杂得多,用户可以使用更多的高级功能(如分页)。CPU 必须中途将实模式切换为保护模式。但是,这种切换是单向的,即不能从保护模式再切换回实模式。
内核初始化的第一步是执行实模式下的汇编代码,之后执行保护模式下init/main.c文件(上一章修改的源文件)中的 start_kernel()函数。start_kernel()函数首先会初始化CPU子系统,之后让内存和进程管理系统就位,接下来启动外部总线和 I/O设备,最后一步是激活初始化(init)程序,它是所有Linux进程的父进程。初始化进程执行启动必要的内核服务的用户空间脚本,并且最终派生控 制台终端程序以及显示登录(login)提示。

图2-1 基于x86硬件上的Linux的启动过程
本节内的3级标题都是图2-2中的一条打印信息,这些信息来源于基于x86的笔记本 电脑的Linux启动过程。如果在其他体系架构上启动内核,消息以及语义可能会有所不同。
2.1.1 BIOS-provided physical RAM map
内核会解析从BIOS中读取到的系统内存映射,并率先将以下信息打印出来:
BIOS-provided physical RAM map:
BIOS-e820: 0000000000000000 - 000000000009f000 (usable)
...
BIOS-e820: 00000000ff800000 - 0000000100000000 (reserved)
实模式下的初始化代码通过使用BIOS的int 0x15服务并执行0xe820号函数(即上面的BIOS-e820字符串)来获得系统的内存映射信息。内存映射信息中包含了预留的和可用的内存,内核将 随后使用这些信息创建其可用的内存池。在附录B的B.1节,我们会对BIOS提供的内存映射问题进行更深入的讲解。
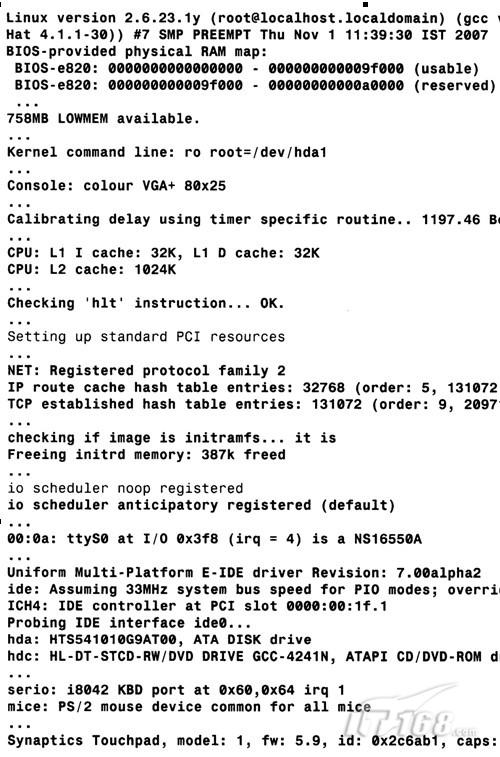
图2-2 内核启动信息
2.1.2 758MB LOWMEM available
896 MB以内的常规的可被寻址的内存区域被称作低端内存。内存分配函数kmalloc()就是从该区域分配内存的。高于896 MB的内存区域被称为高端内存,只有在采用特殊的方式进行映射后才能被访问。
在启动过程中,内核会计算并显示这些内存区内总的页数。
2.1.3 Kernel command line: ro root=/dev/hda1
Linux的引导装入程序通常会给内核传递一个命令行。命令行中的参数类似于传递给C程序中main()函数的argv[]列表,唯一的不同在于它们是传 递给内核的。可以在引导装入程序的配置文件中增加命令行参数,当然,也可以在运行过程中修改引导装入程序的提示行[1]。如果使用的是GRUB 这个引导装入程序,由于发行版本的不同,其配置文件可能是/boot/grub/grub.conf或者是/boot/grub/menu.lst。如果 使用的是LILO,配置文件为/etc/lilo.conf。下面给出了一个grub.conf文件的例子(增加了一些注释),看了紧接着title kernel 2.6.23的那行代码之后,你会明白前述打印信息的由来。
default 0 #Boot the 2.6.23 kernel by default
timeout 5 #5 second to alter boot order or parameters
title kernel 2.6.23 #Boot Option 1
#The boot image resides in the first partition of the first disk
#under the /boot/ directory and is named vmlinuz-2.6.23. 'ro'
#indicates that the root partition should be mounted read-only.
kernel (hd0,0)/boot/vmlinuz-2.6.23 ro root=/dev/hda1
#Look under section "Freeing initrd memory:387k freed"
initrd (hd0,0)/boot/initrd
#...
命令行参数将影响启动过程中的代码执行路径。举一个例子,假设某命令行参数为bootmode,如果该参数被设置为1,意味着你希望在启动过程中打印一些 调试信息并在启动结束时切换到runlevel的第3级(初始化进程的启动信息打印后就会了解runlevel的含义);如果bootmode 参数被设置为0,意味着你希望启动过程相对简洁,并且设置runlevel为2。既然已经熟悉了init/main.c文件,下面就在该文件中增加如下修 改:
static int __init
is_bootmode_setup( char * str)
{
get_option( & str, & bootmode);
return 1 ;
}
/* Handle parameter "bootmode=" */
__setup( " bootmode= " , is_bootmode_setup);
if (bootmode) {
/* Print verbose output */
/* ... */
}
/* ... */
/* If bootmode is 1, choose an init runlevel of 3, else
switch to a run level of 2 */
if (bootmode) {
argv_init[ ++ args] = " 3 " ;
} else {
argv_init[ ++ args] = " 2 " ;
}
/* ... */
请重新编译内核并尝试运行新的修改。
2.1.4 Calibrating delay...1197.46 BogoMIPS (lpj=2394935)
在启动过程中,内核会计算处理器在一个jiffy时间内运行一个内部的延迟循环的次数。jiffy的含义是系统定时器2个连续的节拍之间的间隔。正如所料,该计算必须被校准到所用CPU的处理速度。校准的结果被存储 在称为loops_per_jiffy的内核变量中。使用loops_per_jiffy的一种情况是某设备驱动程序希望进行小的微秒级别的延迟的时候。
为了理解延迟—循环校准代码,让我们看一下定义于init/calibrate.c文件中的calibrate_ delay()函数。该函数灵活地使用整型运算得到了浮点的精度。如下的代码片段(有一些注释)显示了该函数的开始部分,这部分用于得到一个 loops_per_jiffy的粗略值:
printk(KERN_DEBUG “Calibrating delay loop...“);
while ((loops_per_jiffy <<= 1 ) != 0 ) {
ticks = jiffies; /* As you will find out in the section, “Kernel
Timers," the jiffies variable contains the
number of timer ticks since the kernel
started, and is incremented in the timer
interrupt handler */
while (ticks == jiffies); /* Wait until the start of the next jiffy */
ticks = jiffies;
/* Delay */
__delay(loops_per_jiffy);
/* Did the wait outlast the current jiffy? Continue if it didn't */
ticks = jiffies - ticks;
if (ticks) break ;
}
loops_per_jiffy >>= 1 ; /* This fixes the most significant bit and is
the lower-bound of loops_per_jiffy */
上述代码首先假定loops_per_jiffy大于4096,这可以转化为处理器速度大约为每秒100万条指令,即1 MIPS。接下来,它等待jiffy被刷新(1个新的节拍的开始),并开始运行延迟循环__delay(loops_per_jiffy)。如果这个延迟 循环持续了1个jiffy以上,将使用以前的loops_per_jiffy值(将当前值右移1位)修复当前loops_per_jiffy的最高位;否 则,该函数继续通过左移loops_per_jiffy值来探测出其最高位。在内核计算出最高位后,它开始计算低位并微调其精度:
/* Gradually work on the lower-order bits */
while (lps_precision -- && (loopbit >>= 1 )) {
loops_per_jiffy |= loopbit;
ticks = jiffies;
while (ticks == jiffies); /* Wait until the start of the next jiffy */
ticks = jiffies;
/* Delay */
__delay(loops_per_jiffy);
if (jiffies != ticks) /* longer than 1 tick */
loops_per_jiffy &= ~ loopbit;
}
上述代码计算出了延迟循环跨越jiffy边界时loops_per_jiffy的低位值。这个被校准的值可被用于获取BogoMIPS(其实它是一个并非 科学的处理器速度指标)。可以使用BogoMIPS作为衡量处理器运行速度的相对尺度。在1.6G Hz 基于Pentium M的笔记本 电脑上,根据前述启动过程的打印信息,循环校准的结果是:loops_per_jiffy的值为2394935。获得BogoMIPS的方式如下:
= ( 2394935 * HZ * 2 ) / ( 1000000 )
= ( 2394935 * 250 * 2 ) / ( 1000000 )
= 1197.46 (与启动过程打印信息中的值一致)
在2.4节将更深入阐述jiffy、HZ和loops_per_jiffy。
2.1.5 Checking HLT instruction
由于Linux内核支持多种硬件平台,启动代码会检查体系架构相关的bug。其中一项工作就是验证停机(HLT)指令。
x86处理器的HLT指令会将CPU置入一种低功耗睡眠模式,直到下一次硬件中断发生之前维持不变。当内核想让CPU进入空闲状态时(查看 arch/x86/kernel/process_32.c文件中定义的cpu_idle()函数),它会使用HLT指令。对于有问题的CPU而言,命令 行参数no-hlt可以禁止HLT指令。如果no-hlt被设置,在空闲的时候,内核会进行忙等待而不是通过HLT给CPU降温。
当init/main.c中的启动代码调用include/asm-your-arch/bugs.h中定义的check_bugs()时,会打印上述信息。
2.1.6 NET: Registered protocol family 2
Linux套接字(socket)层是用户空间应用程序访问各种网络 协议的统一接口。每个协议通过include/linux/socket.h文件中定义的分配给它的独一无二的系列号注册。上述打印信息中的Family 2代表af_inet(互联网协议)。
启动过程中另一个常见的注册协议系列是AF_NETLINK(Family 16)。网络链接套接字提供了用户进程和内核通信 的 方法。通过网络链接套接字可完成的功能还包括存取路由表和地址解析协议(ARP)表(include/linux/netlink.h文件给出了完整的用 法列表)。对于此类任务而言,网络链接套接字比系统调用更合适,因为前者具有采用异步机制、更易于实现和可动态链接的优点。
内核中经常使能的另一个协议系列是AF_Unix或Unix-domain套接字。X Windows等程序使用它们在同一个系统上进行进程间通信。
2.1.7 Freeing initrd memory: 387k freed
initrd是一种由引导装入程序加载的常驻内存的虚拟磁盘映像。在内核启动后,会将其挂载为初始根文件系统,这个初始根文件系统中存放着挂载实际根文件 系统磁盘分区时所依赖的可动态连接的模块。由于内核可运行于各种各样的存储控制器硬件平台上,把所有可能的磁盘驱动程序都直接放进基本的内核映像中并不可 行。你所使用的系统的存储设备的驱动程序被打包放入了initrd中,在内核启动后、实际的根文件系统被挂载之前,这些驱动程序才被加载。使用 mkinitrd命令可以创建一个initrd映像。
2.6内核提供了一种称为initramfs的新功能,它在几个方面较initrd更为优秀。后者模拟了一个磁盘(因而被称为 initramdisk或initrd),会带来Linux块I/O子系统的开销(如缓冲);前者基本上如同一个被挂载的文件系统一样,由自身获取缓冲 (因此被称作initramfs)。
不同于initrd,基于页缓冲建立的initramfs如同页缓冲一样会动态地变大或缩小,从而减少了其内存消耗。另外,initrd要求你的内核映像 包含initrd所使用的文件系统(例如,如果initrd为EXT2文件系统,内核必须包含EXT2驱动程序),然而initramfs不需要文件系统 支持。再者,由于initramfs只是页缓冲之上的一小层,因此它的代码量很小。
用户可以将初始根文件系统打包为一个cpio压缩包[1],并通过initrd=命令行参数传递给内核。当然,也可以在内核配置过程中通过 INITRAMFS_SOURCE选项直接编译进内核。对于后一种方式而言,用户可以提供cpio压缩包的文件名或者包含initramfs的目录树。在 启动过程中,内核会将文件解压缩为一个initramfs根文件系统,如果它找到了/init,它就会执行该顶层的程序。这种获取初始根文件系统的方法对 于嵌入式系统而言特别有用,因为在嵌入式系统中系统资源非常宝贵。使用mkinitramfs可以创建一个initramfs映像,查看文档 Documentation/filesystems/ramfs- rootfs-initramfs.txt可获得更多信息。
在本例中,我们使用的是通过initrd=命令行参数向内核传递初始根文件系统cpio压缩包的方式。在将压缩包中的内容解压为根文件系统后,内核将释放该压缩包所占据的内存(本例中为387 KB)并打印上述信息。释放后的页面会被分发给内核中的其他部分以便被申请。
在嵌入式系统开发过程中,initrd和initramfs有时候也可被用作嵌入式设备上实际的根文件系统。
2.1.8 io scheduler anticipatory registered (default)
I/O调度器的主要目标是通过减少磁盘的定位次数来增加系统的吞吐率。在磁盘定位过程中,磁头需要从当前的位置移动到感兴趣的目标位置,这会带来一定的延 迟。2.6内核提供了4种不同的I/O调度器:Deadline、Anticipatory、Complete Fair Queuing以及NOOP。从上述内核打印信息可以看出,本例将Anticipatory 设置为了默认的I/O调度器。
2.1.9 Setting up standard PCI resources
启动过程的下一阶段会初始化I/O总线和外围控制器。内核会通过遍历PCI总线来探测PCI硬件,接下来再初始化其他的I/O子系统。从图2-3中我们会看到SCSI子系统、USB控制器、视频 芯片(855北桥芯片组信息中的一部分)、串行端口(本例中为8250 UART)、PS/2键盘 和鼠标 、软驱 、ramdisk、loopback设备、IDE控制器(本例中为ICH4南桥芯片组中的一部分)、触控板、以太网控制器(本例中为e1000)以及PCMCIA控制器初始化的启动信息。图2-3中 符号指向的为I/O设备的标识(ID)。
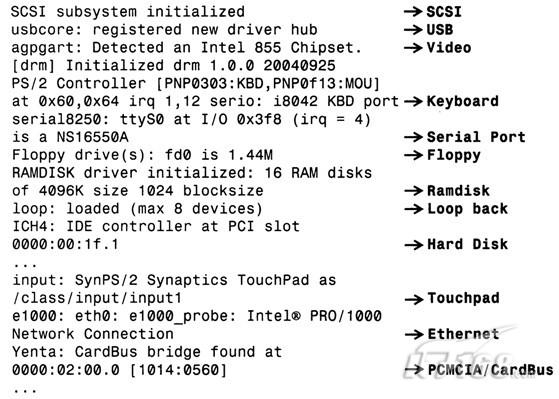
图2-3 在启动过程中初始化总线和外围控制器
本书会以单独的章节讨论大部分上述驱动程序子系统,请注意如果驱动程序以模块的形式被动态链接到内核,其中的一些消息也许只有在内核启动后才会被显示。
2.1.10 EXT3-fs: mounted filesystem
EXT3文件系统已经成为Linux事实上的文件系统。EXT3在退役的EXT2文件系统基础上增添了日志层,该层可用于崩溃后文件系统的快速恢复。它的 目标是不经由耗时的文件系统检查(fsck)操作即可获得一个一致的文件系统。EXT2仍然是新文件系统的工作引擎,但是EXT3层会在进行实际的磁盘改 变之前记录文件交互的日志。EXT3向后兼容于EXT2,因此,你可以在你现存的EXT2文件系统上加上EXT3或者由EXT3返回到EXT2 文件系统。
EXT3会启动一个称为kjournald的内核辅助线程(在接下来的一章中将深入讨论内核线程)来完成日志功能。在EXT3投入运转以后,内核挂载根文件系统并做好“业务”上的准备:
EXT3-fs: mounted filesystem with ordered data mode
kjournald starting. Commit interval 5 seconds
VFS: Mounted root (ext3 filesystem).
2.1.11 INIT: version 2.85 booting
所有Linux进程的父进程init是内核完成启动序列后运行的第1个程序。在init/main.c的最后几行,内核会搜索一个不同的位置以定位到init:
run_init_process(ramdisk_execute_command);
}
if (execute_command) { /* You may override init and ask the kernel
to execute a custom program using the
"init=" kernel command-line argument. If
you do that, execute_command points to the
specified program */
run_init_process(execute_command);
}
/* Else search for init or sh in the usual places .. */
run_init_process( " /sbin/init " );
run_init_process( " /etc/init " );
run_init_process( " /bin/init " );
run_init_process( " /bin/sh " );
panic( " No init found. Try passing init= option to kernel. " );
init会接受/etc/inittab的指引。它首先执行/etc/rc.sysinit中的系统初始化脚本,该脚本的一项最重要的职责就是激活对换(swap)分区,这会导致如下启动信息被打印:
Adding 1552384k swap on /dev/hda6
让我们来仔细看看上述这段话的意思。Linux用户进程拥有3 GB的虚拟地址空间(见2.7节),构成“工作集”的页被保存在RAM中。但是,如果有太多程序需要内存资源,内核会释放一些被使用了的RAM页面并将其 存储到称为对换空间(swap space)的磁盘分区中。根据经验法则,对换分区的大小应该是RAM的2倍。在本例中,对换空间位于/dev/hda6这个磁盘分区,其大小为1 552 384 KB。
接下来,init开始运行/etc/rc.d/rcX.d/目录中的脚本, 其中X是inittab中定义的运行级别。runlevel是根据预期的工作模式所进入的执行状态。例如,多用户文本模式意味着runlevel为3,X Windows则意味着runlevel为5。因此,当你看到INIT: Entering runlevel 3这条信息的时候,init就已经开始执行/etc/rc.d/rc3.d/目录中的脚本了。这些脚本会启动动态设备命名子系统(第4章中将讨论 udev),并加载网络、音频、存储设备等驱动程序所对应的内核模块:
Starting udev: [ OK ]
Initializing hardware... network audio storage [Done]
...
最后,init发起虚拟控制台终端,你现在就可以登录了。
2.2 内核模式和用户模式
MS-DOS等操作系统 在单一的CPU模式下运行,但是一些类Unix的操作系统则使用了双模式,可以有效地实现时间共享。在Linux机器上,CPU要么处于受信任的内核模式,要么处于受限制的用户模式。除了内核本身处于内核模式以外,所有的用户进程都运行在用户模式之中。
内核模式的代码可以无限制地访问所有处理器指令集以及全部内存和I/O空间。如果用户模式的进程要享有此特权,它必须通过系统调用向设备驱动程序或其他内核模式的代码发出请求。另外,用户模式的代码允许发生缺页,而内核模式的代码则不允许。
在2.4和更早的内核中,仅仅用户模式的进程可以被上下文切换出局,由其他进程抢占。除非发生以下两种情况,否则内核模式代码可以一直独占CPU:
(1) 它自愿放弃CPU;
(2) 发生中断或异常。
2.6内核引入了内核抢占,大多数内核模式的代码也可以被抢占。
2.3 进程上下文和中断上下文
内核可以处于两种上下文:进程上下文和中断上下文。在系统调用之后,用户应用程序进入内核空间,此后内核空间针对用户空间相应进程的代表就运行于进程上下 文。异步发生的中断会引发中断处理程序被调用,中断处理程序就运行于中断上下文。中断上下文和进程上下文不可能同时发生。
运行于进程上下文的内核代码是可抢占的,但进程上下文则会一直运行至结束,不会被抢占。因此,内核会限制中断上下文的工作,不允许其执行如下操作:
(1) 进入睡眠状态或主动放弃CPU;
(2) 占用互斥体;
(3) 执行耗时的任务;
(4) 访问用户空间虚拟内存。
本书4.2节会对中断上下文进行更深入的讨论。
2.4 内核定时器
内核中许多部分的工作都高度依赖于时间信息。Linux内核利用硬件提供的不同的定时器以支持忙等待或睡眠等待等时间相关的服务。忙等待时,CPU会不断 运转。但是睡眠等待时,进程将放弃CPU。因此,只有在后者不可行的情况下,才考虑使用前者。内核也提供了某些便利,可以在特定的时间之后调度某函数运 行。
我们首先来讨论一些重要的内核定时器变量(jiffies、HZ和xtime)的含义。接下来,我们会使用Pentium时间戳计数器(TSC)测量基于Pentium的系统的运行次数。之后,我们也分析一下Linux怎么使用实时钟(RTC)。
2.4.1 HZ和Jiffies
系统定时器能以可编程的频率中断处理器。此频率即为每秒的定时器节拍数,对应着内核变量HZ。选择合适的HZ值需要权衡。HZ值大,定时器间隔时间就小,因此进程调度的准确性会更高。但是,HZ值越大也会导致开销和电源 消耗更多,因为更多的处理器周期将被耗费在定时器中断上下文中。
2.6 .21内核支持无节拍的内核(CONFIG_NO_HZ),它会根据系统的负载动态触发定时器中断。无节拍系统的实现超出了本章的讨论范围,不再详述。
jiffies变量记录了系统启动以来,系统定时器已经触发的次数。内核每秒钟将jiffies变量增加HZ次。因此,对于HZ值为100的系统,1个jiffy等于10ms,而对于HZ为1000的系统,1个jiffy仅为1ms。
为了更好地理解HZ和jiffies变量,请看下面的取自IDE驱动程序(drivers/ide/ide.c)的代码片段。该段代码会一直轮询磁盘驱动器的忙状态:
while (hwgroup -> busy) {
/* ... */
if (time_after(jiffies, timeout)) {
return - EBUSY;
}
/* ... */
}
return SUCCESS;
如果忙条件在3s内被清除,上述代码将返回SUCCESS,否则,返回-EBUSY。3*HZ是3s内的jiffies数量。计算出来的超时 jiffies + 3*HZ将是3s超时发生后新的jiffies值。time_after()的功能是将目前的jiffies值与请求的超时时间对比,检测溢出。类似函数 还包括time_before()、time_before_eq()和time_after_eq()。
jiffies被定义为volatile类型,它会告诉编译器不要优化该变量的存取代码。这样就确保了每个节拍发生的定时器中断处理程序都能更新jiffies值,并且循环中的每一步都会重新读取jiffies值。
对于jiffies向秒转换,可以查看USB主机控制器驱动程序drivers/usb/host/ehci-sched.c中的如下代码片段:
ehci_info(ehci, " ep%ds-iso rescheduled " " %lu times in %lu
seconds\n " , stream->bEndpointAddress, is_in? " in " :
" out " , stream -> rescheduled,
((jiffies – stream -> start) / HZ));
}
上述调试语句计算出USB端点流(见第11章)被重新调度stream->rescheduled次所耗费的秒数。jiffies-stream->start是从开始到现在消耗的jiffies数量,将其除以HZ就得到了秒数值。
假定jiffies值为1000,32位的jiffies会在大约50天的时间内溢出。由于系统的运行时间可以比该时间长许多倍,因此,内核提供了另一个 变量jiffies_64以存放64位(u64)的jiffies。链接器将jiffies_64的低32位与32位的jiffies指向同一个地址。在 32位的机器上,为了将一个u64变量赋值给另一个,编译器需要2条指令,因此,读jiffies_64的操作不具备原子性。可以将 drivers/cpufreq/cpufreq_stats.c文件中定义的cpufreq_stats_update()作为实例来学习。
2.4.2 长延时
在内核中,以jiffies为单位进行的延迟通常被认为是长延时。一种可能但非最佳的实现长延时的方法是忙等待。实现忙等待的函数有“占着茅坑不拉屎”之嫌,它本身不利用CPU进行有用的工作,同时还不让其他程序使用CPU。如下代码将占用CPU 1秒:
unsigned long timeout = jiffies + HZ;
while (time_before(jiffies, timeout)) continue;
实现长延时的更好方法是睡眠等待而不是忙等待,在这种方式中,本进程会在等待时将处理器出让给其他进程。schedule_timeout()完成此功能:
unsigned long timeout = HZ;
schedule_timeout(timeout); /* Allow other parts of the kernel to run */
这种延时仅仅确保超时较低时的精度。由于只有在时钟节拍引发的内核调度才会更新jiffies,所以无论是在内核空间还是在用户空间,都很难使超时的精度 比HZ更大了。另外,即使你的进程已经超时并可被调度,但是调度器仍然可能基于优先级策略选择运行队列的其他进程[1]。
用于睡眠等待的另2个函数是wait_event_timeout()和msleep(),它们的实现都基于 schedule_timeout()。wait_event_timeout()的使用场合是:在一个特定的条件满足或者超时发生后,希望代码继续运 行。msleep()表示睡眠指定的时间(以毫秒为单位)。
这种长延时技术仅仅适用于进程上下文。睡眠等待不能用于中断上下文,因为中断上下文不允许执行schedule()或睡眠(4.2节给出了中断上下文可以 做和不能做的事情)。在中断中进行短时间的忙等待是可行的,但是进行长时间的忙等则被认为不可赦免的罪行。在中断禁止时,进行长时间的忙等待也被看作禁 忌。
为了支持在将来的某时刻进行某项工作,内核也提供了定时器API。可以通过init_timer()动态定义一个定时器,也可以通过 DEFINE_TIMER()静态创建定时器。然后,将处理函数的地址和参数绑定给一个timer_list,并使用add_timer()注册它即可:
struct timer_list my_timer;
init_timer( & my_timer); /* Also see setup_timer() */
my_timer.expire = jiffies + n * HZ; /* n is the timeout in number of seconds */
my_timer.function = timer_func; /* Function to execute after n seconds */
my_timer.data = func_parameter; /* Parameter to be passed to timer_func */
add_timer( & my_timer); /* Start the timer */
上述代码只会让定时器运行一次。如果想让timer_func()函数周期性地执行,需要在timer_func()加上相关代码,指定其在下次超时后调度自身:
{
/* Do work to be done periodically */
/* ... */
init_timer( & my_timer);
my_timer.expire = jiffies + n * HZ;
my_timer.data = func_parameter;
my_timer.function = timer_func;
add_timer( & my_timer);
}
你可以使用mod_timer()修改my_timer的到期时间,使用del_timer()取消定时器,或使用 timer_pending()以查看my_timer当前是否处于等待状态。查看kernel/timer.c源代码,会发现 schedule_timeout()内部就使用了这些API。
clock_settime()和clock_gettime()等用户空间函数可用于获得内核定时器服务。用户应用程序可以使用setitimer()和getitimer()来控制一个报警信号在特定的超时后发生。
2.4.3 短延时
在内核中,小于jiffy的延时被认为是短延时。这种延时在进程或中断上下文都可能发生。由于不可能使用基于jiffy的方法实现短延时,之前讨论的睡眠等待将不再能用于短的超时。这种情况下,唯一的解决途径就是忙等待。
实现短延时的内核API包括mdelay()、udelay()和ndelay(),分别支持毫秒、微秒和纳秒级的延时。这些函数的实际实现取决于体系架构,而且也并非在所有平台上都被完整实现。
忙等待的实现方法是测量处理器执行一条指令的时间,为了延时,执行一定数量的指令。从前文可知,内核会在启动过程中进行测量并将该值存储在 loops_per_jiffy变量中。短延时API就使用了loops_per_jiffy值来决定它们需要进行循环的数量。为了实现握手进程中1微秒 的延时,USB主机控制器驱动程序(drivers/usb/host/ehci-hcd.c)会调用udelay(),而udelay()会内部调用 loops_per_jiffy:
result = ehci_readl(ehci, ptr);
/* ... */
if (result == done) return 0 ;
udelay( 1 ); /* Internally uses loops_per_jiffy */
usec -- ;
} while (usec > 0 );
2.4.4 Pentium时间戳计数器
时间戳计数器(TSC)是Pentium兼容处理器中的一个计数器,它记录自启动以来处理器消耗的时钟周期数。由于TSC随着处理器周期速率的比例的变化 而变化,因此提供了非常高的精确度。TSC通常被用于剖析和监测代码。使用rdtsc指令可测量某段代码的执行时间,其精度达到微秒级。TSC 的节拍可以被转化为秒,方法是将其除以CPU时钟速率(可从内核变量cpu_khz读取)。
在如下代码片段中,low_tsc_ticks和high_tsc_ticks分别包含了TSC的低32位和高32位。低32位可能在数秒内溢出(具体时间取决于处理器速度),但是这已经用于许多代码的剖析了:
unsigned long low_tsc_ticks1, high_tsc_ticks1;
unsigned long exec_time;
rdtsc(low_tsc_ticks0, high_tsc_ticks0); /* Timestamp before */
printk( " Hello World\n " ); /* Code to be profiled */
rdtsc(low_tsc_ticks1, high_tsc_ticks1); /* Timestamp after */
exec_time = low_tsc_ticks1 - low_tsc_ticks0;
在1.8 GHz Pentium 处理器上,exec_time的结果为871(或半微秒)。
2.4.5 实时钟
RTC在非易失性存储器上记录绝对时间。在x86 PC上,RTC位于由电池供电[1]的互补金属氧化物半导体(CMOS)存储器的顶部。从第5章的图5-1可以看出传统PC体系架构中CMOS的位置。在 嵌入式系统中,RTC可能被集成到处理器中,也可能通过I2C或SPI总线在外部连接,见第8章。
使用RTC可以完成如下工作:
(1) 读取、设置绝对时间,在时钟更新时产生中断;
(2) 产生频率为2~8192 Hz之间的周期性中断;
(3) 设置报警信号。
许多应用程序需要使用绝对时间[或称墙上时间(wall time)]。jiffies是相对于系统启动后的时间,它不包含墙上时间。内核将墙上时间记录在xtime变量中,在启动过程中,会根据从RTC读取到 的目前的墙上时间初始化xtime,在系统停机后,墙上时间会被写回RTC。你可以使用do_gettimeofday()读取墙上时间,其最高精度由硬 件决定:
static struct timeval curr_time;
do_gettimeofday( & curr_time);
my_timestamp = cpu_to_le32(curr_time.tv_sec); /* Record timestamp */
用户空间也包含一系列可以访问墙上时间的函数,包括:
(1) time(),该函数返回日历时间,或从新纪元(1970年1月1日00:00:00)以来经历的秒数;
(2) localtime(),以分散的形式返回日历时间;
(3) mktime(),进行localtime()函数的反向工作;
(4) gettimeofday(),如果你的平台支持,该函数将以微秒精度返回日历时间。
用户空间使用RTC的另一种途径是通过字符设备/dev/rtc来进行,同一时刻只有一个进程允许返回该字符设备。
在第5章和第8章,本书将更深入讨论RTC驱动程序。另外,在第19章给出了一个使用/dev/rtc以微秒级精度执行周期性工作的应用程序示例。
2.5 内核中的并发
随着多核笔记本电脑时代的到来,对称多处理器(SMP)的使用不再被限于高科技用户。SMP和内核抢占是多线程执行的两种场景。多个线程能够同时操作共享的内核数据结构,因此,对这些数据结构的访问必须被串行化。
接下来,我们会讨论并发访问情况下保护共享内核资源的基本概念。我们以一个简单的例子开始,并逐步引入中断、内核抢占和SMP等复杂概念。
2.5.1 自旋锁和互斥体
访问共享资源的代码区域称作临界区。自旋锁(spinlock)和互斥体(mutex,mutual exclusion的缩写)是保护内核临界区的两种基本机制。我们逐个分析。
自旋锁可以确保在同时只有一个线程进入临界区。其他想进入临界区的线程必须不停地原地打转,直到第1个线程释放自旋锁。注意:这里所说的线程不是内核线程,而是执行的线程。
下面的例子演示了自旋锁的基本用法:
spinlock_t mylock = SPIN_LOCK_UNLOCKED; /* Initialize */
/* Acquire the spinlock. This is inexpensive if there
* is no one inside the critical section. In the face of
* contention, spinlock() has to busy-wait.
*/
spin_lock( & mylock);
/* ... Critical Section code ... */
spin_unlock( & mylock); /* Release the lock */
与自旋锁不同的是,互斥体在进入一个被占用的临界区之前不会原地打转,而是使当前线程进入睡眠状态。如果要等待的时间较长,互斥体比自旋锁更合适,因为自 旋锁会消耗CPU资源。在使用互斥体的场合,多于2次进程切换时间都可被认为是长时间,因此一个互斥体会引起本线程睡眠,而当其被唤醒时,它需要被切换回 来。
因此,在很多情况下,决定使用自旋锁还是互斥体相对来说很容易:
(1) 如果临界区需要睡眠,只能使用互斥体,因为在获得自旋锁后进行调度、抢占以及在等待队列上睡眠都是非法的;
(2) 由于互斥体会在面临竞争的情况下将当前线程置于睡眠状态,因此,在中断处理函数中,只能使用自旋锁。(第4章将介绍更多的关于中断上下文的限制。)
下面的例子演示了互斥体使用的基本方法:
/* Statically declare a mutex. To dynamically
create a mutex, use mutex_init() */
static DEFINE_MUTEX(mymutex);
/* Acquire the mutex. This is inexpensive if there
* is no one inside the critical section. In the face of
* contention, mutex_lock() puts the calling thread to sleep.
*/
mutex_lock( & mymutex);
/* ... Critical Section code ... */
mutex_unlock( & mymutex); /* Release the mutex */
为了论证并发保护的用法,我们首先从一个仅存在于进程上下文的临界区开始,并以下面的顺序逐步增加复杂性:
(1) 非抢占内核,单CPU情况下存在于进程上下文的临界区;
(2) 非抢占内核,单CPU情况下存在于进程和中断上下文的临界区;
(3) 可抢占内核,单CPU情况下存在于进程和中断上下文的临界区;
(4) 可抢占内核,SMP情况下存在于进程和中断上下文的临界区。
旧的信号量接口
互斥体接口代替了旧的信号量接口(semaphore)。互斥体接口是从-rt树演化而来的,在2.6.16内核中被融入主线内核。
尽管如此,但是旧的信号量仍然在内核和驱动程序中广泛使用。信号量接口的基本用法如下:
/* Statically declare a semaphore. To dynamically
create a semaphore, use init_MUTEX() */
static DECLARE_MUTEX(mysem);
down( & mysem); /* Acquire the semaphore */
/* ... Critical Section code ... */
up( & mysem); /* Release the semaphore */
1. 案例1:进程上下文,单CPU,非抢占内核
这种情况最为简单,不需要加锁,因此不再赘述。
2. 案例2:进程和中断上下文,单CPU,非抢占内核
在这种情况下,为了保护临界区,仅仅需要禁止中断。如图2-4所示,假定进程上下文的执行单元A、B以及中断上下文的执行单元C都企图进入相同的临界区。

图2-4 进程和中断上下文进入临界区
由于执行单元C总是在中断上下文执行,它会优先于执行单元A和B,因此,它不用担心保护的问题。执行单元A和B也不必关心彼此会被互相打断,因为内核是非 抢占的。因此,执行单元A和B仅仅需要担心C会在它们进入临界区的时候强行进入。为了实现此目的,它们会在进入临界区之前禁止中断:
local_irq_disable(); /* Disable Interrupts in local CPU */
/* ... Critical Section ... */
local_irq_enable(); /* Enable Interrupts in local CPU */
但是,如果当执行到Point A的时候已经被禁止,local_irq_enable()将产生副作用,它会重新使能中断,而不是恢复之前的中断状态。可以这样修复它:
Point A:
local_irq_save(flags); /* Disable Interrupts */
/* ... Critical Section ... */
local_irq_restore(flags); /* Restore state to what it was at Point A */
不论Point A的中断处于什么状态,上述代码都将正确执行。
3. 案例3:进程和中断上下文,单CPU,抢占内核
如果内核使能了抢占,仅仅禁止中断将无法确保对临界区的保护,因为另一个处于进程上下文的执行单元可能会进入临界区。重新回到图2-4,现在,除了C以 外,执行单元A和B必须提防彼此。显而易见,解决该问题的方法是在进入临界区之前禁止内核抢占、中断,并在退出临界区的时候恢复内核抢占和中断。因此,执 行单元A和B使用了自旋锁API的irq变体:
Point A:
/* Save interrupt state.
* Disable interrupts - this implicitly disables preemption */
spin_lock_irqsave( & mylock, flags);
/* ... Critical Section ... */
/* Restore interrupt state to what it was at Point A */
spin_unlock_irqrestore( & mylock, flags);
我们不需要在最后显示地恢复Point A的抢占状态,因为内核自身会通过一个名叫抢占计数器的变量维护它。在抢占被禁止时(通过调用preempt_disable()),计数器值会增加;在 抢占被使能时(通过调用preempt_enable()),计数器值会减少。只有在计数器值为0的时候,抢占才发挥作用。
4. 案例4:进程和中断上下文,SMP机器,抢占内核
现在假设临界区执行于SMP机器上,而且你的内核配置了CONFIG_SMP和CONFIG_PREEMPT。
到目前为止讨论的场景中,自旋锁原语发挥的作用仅限于使能和禁止抢占和中断,时间的锁功能并未被完全编译进来。在SMP机器内,锁逻辑被编译进来,而且自旋锁原语确保了SMP安全 性。SMP使能的含义如下:
Point A:
/*
- Save interrupt state on the local CPU
- Disable interrupts on the local CPU. This implicitly disables preemption.
- Lock the section to regulate access by other CPUs
*/
spin_lock_irqsave( & mylock, flags);
/* ... Critical Section ... */
/*
- Restore interrupt state and preemption to what it
was at Point A for the local CPU
- Release the lock
*/
spin_unlock_irqrestore( & mylock, flags);
在SMP系统上,获取自旋锁时,仅仅本CPU上的中断被禁止。因此,一个进程上下文的执行单元(图2-4中的执行单元A)在一个CPU上运行的同时,一个 中断处理函数(图2-4中的执行单元C)可能运行在另一个CPU上。非本CPU上的中断处理函数必须自旋等待本CPU上的进程上下文代码退出临界区。中断 上下文需要调用spin_lock()/spin_unlock():
/* ... Critical Section ... */
spin_unlock( & mylock);
除了有irq变体以外,自旋锁也有底半部(BH)变体。在锁被获取的时候,spin_lock_bh()会禁止底半部,而spin_unlock_bh()则会在锁被释放时重新使能底半部。我们将在第4章讨论底半部。
-rt树
实时(-rt)树,也被称作CONFIG_PREEMPT_RT补丁集,实现了内核中一些针对低延时的修改。该补丁集可以从 www.kernel.org/pub/linux/kernel/projects/rt下载,它允许内核的大部分位置可被抢占,但是用自旋锁代替了一 些互斥体。它也合并了一些高精度的定时器。数个-rt功能已经被融入了主线内核。详细的文档见http://rt.wiki.kernel.org/。
为了提高性能,内核也定义了一些针对特定环境的特定的锁原语。使能适用于代码执行场景的互斥机制将使代码更高效。下面来看一下这些特定的互斥机制。
2.5.2 原子操作
原子操作用于执行轻量级的、仅执行一次的操作,例如修改计数器、有条件的增加值、设置位等。原子操作可以确保操作的串行化,不再需要锁进行并发访问保护。原子操作的具体实现取决于体系架构。
为了在释放内核网络缓冲区(称为skbuff)之前检查是否还有余留的数据引用,定义于net/core/skbuff.c文件中的skb_release_data()函数将进行如下操作:
2 /* Atomically decrement and check if the returned value is zero */
3 ! atomic_sub_return(skb -> nohdr ? ( 1 << SKB_DATAREF_SHIFT) + 1 :
4 1 , & skb_shinfo(skb) -> dataref)) {
5 /* ... */
6 kfree(skb -> head);
7 }
当skb_release_data()执行的时候,另一个调用skbuff_clone()(也在net/core/skbuff.c文件中定义)的执行单元也许在同步地增加数据引用计数值:
/* Atomically bump up the data reference count */
atomic_inc( & (skb_shinfo(skb) -> dataref));
/* ... */
原子操作的使用将确保数据引用计数不会被这两个执行单元“蹂躏”。它也消除了使用锁去保护单一整型变量的争论。
内核也支持set_bit()、clear_bit()和test_and_set_bit()操作,它们可用于原子地位修改。查看include/asm-your-arch/atomic.h文件可以看出你所在体系架构所支持的原子操作。
2.5.3 读—写锁
另一个特定的并发保护机制是自旋锁的读—写锁变体。如果每个执行单元在访问临界区的时候要么是读要么是写共享的数据结构,但是它们都不会同时进行读和写操作,那么这种锁是最好的选择。允许多个读线程同时进入临界区。读自旋锁可以这样定义:
read_lock( & myrwlock); /* Acquire reader lock */
/* ... Critical Region ... */
read_unlock( & myrwlock); /* Release lock */
但是,如果一个写线程进入了临界区,那么其他的读和写都不允许进入。写锁的用法如下:
write_lock( & myrwlock); /* Acquire writer lock */
/* ... Critical Region ... */
write_unlock( & myrwlock); /* Release lock */
net/ipx/ipx_route.c中的IPX路由代码是使用读—写锁的真实示例。一个称作ipx_routes_lock的读—写锁将保护IPX路 由表的并发访问。要通过查找路由表实现包转发的执行单元需要请求读锁。需要添加和删除路由表中入口的执行单元必须获取写锁。由于通过读路由表的情况比更新 路由表的情况多得多,使用读—写锁提高了性能。
和传统的自旋锁一样,读—写锁也有相应的irq变体:read_lock_irqsave()、read_unlock_ irqrestore()、write_lock_irqsave()和write_unlock_irqrestore()。这些函数的含义与传统自旋 锁相应的变体相似。
2.6内核引入的顺序锁(seqlock)是一种支持写多于读的读—写锁。在一个变量的写操作比读操作多得多的情况下,这种锁非常有用。前文讨论的jiffies_64变量就是使用顺序锁的一个例子。写线程不必等待一个已经进入临界区的读,因此,读线程也许会发现它们进入临界区的操作失败,因此需要重试:
{
unsigned long seq;
u64 ret;
do {
seq = read_seqbegin( & xtime_lock);
ret = jiffies_64;
} while (read_seqretry( & xtime_lock, seq));
return ret;
}
写者会使用write_seqlock()和write_sequnlock()保护临界区。
2.6内核还引入了另一种称为读—复制—更新(RCU)的机制。 该机制用于提高读操作远多于写操作时的性能。其基本理念是读线程不需要加锁,但是写线程会变得更加复杂,它们会在数据结构的一份副本上执行更新操作,并代 替读者看到的指针。为了确保所有正在进行的读操作的完成,原子副本会一直被保持到所有CPU上的下一次上下文切换。使用RCU的情况很复杂,因此,只有在 确保你确实需要使用它而不是前文的其他原语的时候,才适宜选择它。 include/linux/ rcupdate.h文件中定义了RCU的数据结构和接口函数,Documentation/RCU/*提供了丰富的文档。
fs/dcache.c文件中包含一个RCU的使用示例。在Linux中,每个文件都与一个目录入口信息(dentry结构体)、元数据信息 (存放在inode中)和实际的数据(存放在数据块中)关联。每次操作一个文件的时候,文件路径中的组件会被解析,相应的dentry会被获取。为了加速 未来的操作,dentry结构体被缓存在称为dcache的数据结构中。任何时候,对dcache进行查找的数量都远多于dcache的更新操作,因此, 对dcache的访问适宜用RCU原语进行保护。
2.5.4 调试
由于难于重现,并发相关的问题通常非常难调试。在编译和测试代码的时候使能SMP(CONFIG_SMP)和抢占 (CONFIG_PREEMPT)是一种很好的理念,即便你的产品将运行在单CPU、禁止抢占的情况下。在Kernel hacking下有一个称为Spinlock and rw-lock debugging的配置选项(CONFIG_DEBUG_SPINLOCK),它能帮助你找到一些常见的自旋锁错误。 Lockmeter(http://oss.sgi. com/projects/lockmeter/)等工具可用于收集锁相关的统计信息。
在访问共享资源之前忘记加锁就会出现常见的并发问题。这会导致一些不同的执行单元杂乱地“竞争”。这种问题(被称作“竞态”)可能会导致一些其他的行为。
在某些代码路径里忘记了释放锁也会出现并发问题,这会导致死锁。为了理解这个问题,让我们分析如下代码:
/* ... Critical Section ... */
if (error) { /* This error condition occurs rarely */
return - EIO; /* Forgot to release the lock! */
}
spin_unlock( & mylock); /* Release lock */
if (error)语句成立的话,任何要获取mylock的线程都会死锁,内核也可能因此而冻结。
如果在写完代码的数月或数年以后首次出现了问题,回过头来调试它将变得更为棘手。(在21.3.3节有一个相关的调试例子。)因此,为了避免遭遇这种不快,在设计软件 架构的时候,就应该考虑并发逻辑。
2.6 proc文件系统
proc文件系统(procfs)是一种虚拟的文件系统,它创建内核内部的视窗。浏览procfs时看到的数据是在内核运行过程中产生的。procfs中的文件可被用于配置内核参数、查看内核结构体、从设备驱动程序中收集统计信息或者获取通用的系统信息。
procfs是一种虚拟的文件系统,这意味着驻留于procfs中的文件并不与物理存储设备如硬盘 等关联。相反,这些文件中的数据由内核中相应的入口点按需动态创建。因此,procfs中的文件大小都显示为0。procfs通常在启动过程中挂载在/proc目录,通过运行mount命令可以看出这一点。
为了了解procfs的能力,请查看/proc/cpuinfo、/proc/meminfo、/proc/interrupts、/proc /tty/driver /serial、/proc/bus/usb/devices和/proc/stat的内容。通过写/proc/sys/目录中的文件可以在运行时修改某 些内核参数。例如,通过向/proc/sys/kernel/printk文件回送一个新的值,可以改变内核printk日志的级别。许多实用程序(如 ps)和系统性能监视工具(如sysstat)就是通过驻留于/proc中的文件来获取信息的。
2.6内核引入的seq文件简化了大的procfs操作。附录C对此进行了描述。
2.7 内存分配
一些设备驱动程序必须意识到内存区的存在,另外,许多驱动程序需要内存分配函数的服务。本节我们将简要地讨论这两点。
内核会以分页形式组织物理内存,而页大小则取决于具体的体系架构。在基于x86的机器上,其大小为4096B。物理内存中的每一页都有一个与之对应的struct page(定义在include/linux/ mm_types.h文件中):
在32位x86系统上,默认的内核配置会将4 GB的地址空间分成给用户空间的3 GB的虚拟内存空间和给内核空间的1 GB的空间(如图2-5所示)。这导致内核能处理的处理内存有1 GB的限制。现实情况是,限制为896 MB,因为地址空间的128 MB已经被内核数据结构占据。通过改变3 GB/1 GB的分割线,可以放宽这个限制,但是由于减少了用户进程虚拟地址空间的大小,在内存密集型的应用程序中可能会出现一些问题。
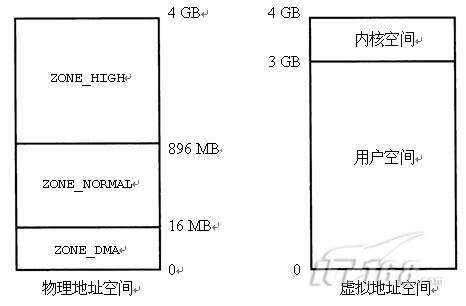
图2-5 32位PC系统上默认的地址空间分布
内核中用于映射低于896 MB物理内存的地址与物理地址之间存在线性偏移;这种内核地址被称作逻辑地址。在支持“高端内存”的情况下,在通过特定的方式映射这些区域产生对应的虚拟地址后,内核将能访问超过896 MB的内存。所有的逻辑地址都是内核虚拟地址,而所有的虚拟地址并非一定是逻辑地址。
因此,存在如下的内存区。
(1) ZONE_DMA(小于16 MB),该区用于直接内存访问(DMA)。由于传统的ISA设备有24条地址线,只能访问开始的16 MB,因此,内核将该区献给了这些设备。
(2) ZONE_NORMAL(16~896 MB),常规地址区域,也被称作低端内存。用于低端内存页的struct page结构中的“虚拟”字段包含了对应的逻辑地址。
(3) ZONE_HIGH(大于896 MB),仅仅在通过kmap()映射页为虚拟地址后才能访问。(通过kunmap()可去除映射。)相应的内核地址为虚拟地址而非逻辑地址。如果相应的页 未被映射,用于高端内存页的struct page结构体的“虚拟”字段将指向NULL。
kmalloc()是一个用于从ZONE_NORMAL区域返回连续内存的内存分配函数,其原型如下:
void *kmalloc(int count, int flags);
count是要分配的字节数,flags是一个模式说明符。支持的所有标志列在include/linux./gfp.h文件中(gfp是get free page的缩写),如下为常用标志。
(1) GFP_KERNEL,被进程上下文用来分配内存。如果指定了该标志,kmalloc()将被允许睡眠,以等待其他页被释放。
(2) GFP_ATOMIC,被中断上下文用来获取内存。在这种模式下,kmalloc()不允许进行睡眠等待,以获得空闲页,因此GFP_ATOMIC分配成功的可能性比用GFP_KERNEL低。
由于kmalloc()返回的内存保留了以前的内容,将它暴露给用户空间可到会导致安全问题,因此我们可以使用kzalloc()获得被填充为0的内存。
如果需要分配大的内存缓冲区,而且也不要求内存在物理上有联系,可以用vmalloc()代替kmalloc():
void *vmalloc(unsigned long count);
count是要请求分配的内存大小。该函数返回内核虚拟地址。
vmalloc()需要比kmalloc()更大的分配空间,但是它更慢,而且不能从中断上下文调用。另外,不能用vmalloc()返回的物理上不连续的内存执行DMA。在设备打开时,高性能的网络驱动程序通常会使用vmalloc()来分配较大的描述符环行缓冲区。
内核还提供了一些更复杂的内存分配技术,包括后备缓冲区(look aside buffer)、slab和mempool;这些概念超出了本章的讨论范围,不再细述。
2.8 查看源代码
内存启动始于执行arch/x86/boot/目录中的实模式汇编代码。查看arch/x86/kernel/setup_32.c文件可以看出保护模式的内核怎样获取实模式内核收集的信息。
第一条信息来自于init/main.c中的代码,深入挖掘init/calibrate.c可以对BogoMIPS校准理解得更清楚,而include/asm-your-arch/bugs.h则包含体系架构相关的检查。
内核中的时间服务由驻留于arch/your-arch/kernel/中的体系架构相关的部分和实现于kernel/timer.c中的通用部分组成。从include/linux/time*.h头文件中可以获取相关的定义。
jiffies定义于linux/jiffies.h文件中。HZ的值与处理器相关,可以从include/asm-your-arch/ param.h找到。
内存管理源代码存放在顶层mm/目录中。
表2-1给出了本章中主要的数据结构以及其在源代码树中定义的位置。表2-2则列出了本章中主要内核编程接口及其定义的位置。
表2-1 数据结构小结

表2-2 内核编程接口小结
- 微信扫码赞助
-

- 支付宝赞助
-

2015/08/10 18:46:54
RGsUhN http://www.FyLitCl7Pf7kjQdDUOLQOuaxTXbj5iNG.com
2015/05/16 09:44:28
pretty good blog,come again next time。
2015/05/14 16:18:05
不止一次的来访,一如既往的支持。